

Découvrez comment configurer Prometheus et Grafana pour obtenir une observabilité complète sur Kubernetes. Apprenez à déployer Prometheus avec le Prometheus Operator et à créer des tableaux de bord visuels et dynamiques avec Grafana
L’observabilité est un pilier essentiel des meilleures pratiques DevOps, offrant des informations cruciales sur la performance et la santé des systèmes. Dans des environnements complexes comme Kubernetes avec des microservices et des services distribués, l’observabilité devient encore plus indispensable.
Kubernetes est conçu pour gérer des services à grande échelle, mais surveiller des milliers d’applications devient complexe avec des méthodes manuelles ou des scripts. Il est donc crucial de mettre en place un système d’observabilité capable de suivre cette échelle. C’est là que Prometheus et Grafana entrent en jeu.
Prometheus est spécialisé dans la collecte et le stockage des métriques de votre cluster, offrant une vue détaillée de son état et de sa performance. De son côté, Grafana se connecte à Prometheus pour vous permettre de concevoir des dashboards et des visualisations claires et dynamiques.
Dans cet article, nous vous guiderons à travers le déploiement de Prometheus sur Kubernetes en utilisant le Prometheus Operator, puis nous configurerons Grafana pour visualiser ces données. Ce tutoriel vous fournira une base solide pour mettre en place l’observabilité de votre infrastructure et optimiser vos processus DevOps.
Qu’est-ce que l’Observabilité ?
L’observabilité est la capacité à mesurer et à comprendre l’état interne d’un système complexe en se basant sur ses sorties visibles. Contrairement au monitoring traditionnel, qui se concentre souvent sur la collecte de métriques prédéfinies, l’observabilité vise à offrir une vue complète de la performance et de la santé d’une infrastructure en capturant des données plus variées et approfondies.
L'observabilité repose sur trois pilliers :
- Les Logs : Les logs fournissent une trace détaillée des événements qui se produisent dans le système. Ils permettent de diagnostiquer des problèmes en offrant des informations contextuelles sur ce qui s’est passé avant, pendant et après un incident.
- Les Métriques : Les métriques sont des mesures quantitatives sur les performances du système, comme le taux d’utilisation du CPU, la latence des requêtes ou le nombre de requêtes traitées. Elles permettent de suivre l’évolution des performances au fil du temps et d’identifier des tendances ou des anomalies.
- Les Traces : Les traces suivent le parcours d’une requête à travers les différents services d’une application. Elles permettent de comprendre le chemin complet d’une opération, d’identifier les goulets d’étranglement et de visualiser les interactions entre les composants du système.
Prometheus
Prometheus est une application open-source pour la surveillance des événements et l’alerte, développée par SoundCloud en 2012. Peu de temps après, de nombreuses entreprises et organisations l’ont adoptée et ont contribué à son développement. En 2016, la Cloud Native Computing Foundation (CNCF) a incubé le projet Prometheus après Kubernetes.
Concepts
Prometheus se distingue par son modèle de données basé sur le temps. Il stocke les métriques sous forme de séries temporelles, où chaque série est une paire clé-valeur associée à un horodatage. Ce modèle permet une analyse fine et détaillée des performances des systèmes, en offrant une vue granulaire sur les données collectées.
L’outil utilise un langage de requête puissant appelé PromQL (Prometheus Query Language). Ce langage permet aux utilisateurs d’extraire et d’analyser les données de manière flexible, facilitant la création de requêtes complexes pour filtrer, agréger et visualiser les métriques.
Voici un exemple de requête PromQL :
sum(rate(container_cpu_usage_seconds_total{image!="", pod_name=~".*your-pod-name.*"}[5m])) by (pod_name)• container_cpu_usage_seconds_total : Cette métrique suit l’utilisation totale du CPU par conteneur en secondes.
• image!=”” : Filtre les conteneurs qui ont une image associée, excluant ceux sans image.
• pod_name=~”.your-pod-name.” : Filtre les métriques pour ne montrer que celles des pods dont le nom correspond au pattern “your-pod-name”.
• rate(…[5m]) : Calcule le taux de changement de la métrique au cours des 5 dernières minutes, ce qui vous donne une idée de la consommation CPU récente.
• sum(…) by (pod_name) : Agrège les valeurs par pod, permettant de voir l’utilisation totale du CPU par pod.
Ce type de requête est utile pour surveiller l’utilisation du CPU par pod sur une période donnée, ce qui est essentiel pour identifier les pods qui consomment le plus de ressources et qui pourraient nécessiter une attention particulière.
Architecture
Une caractéristique notable de Prometheus est son architecture de type “pull”. Contrairement à d’autres systèmes de monitoring qui utilisent une approche “push”, Prometheus interroge régulièrement les endpoints configurés pour récupérer les données de métriques. Cette approche simplifie la gestion et la configuration des agents de collecte (exporters).

Le diagramme d’architecture montre que Prometheus est un système de surveillance multi-composants. Les éléments suivants sont intégrés dans le déploiement de Prometheus :
• Serveur Prometheus : Il collecte et stocke les données de séries temporelles. Il offre également une interface utilisateur pour interroger les métriques.
• Bibliothèques clientes : Elles sont utilisées pour instrumenter le code des applications.
• Pushgateway : Il prend en charge la collecte des métriques provenant des tâches éphémères.
• Exportateurs : Ils sont utilisés pour les services qui n’instrumentent pas directement les métriques Prometheus.
• Alertmanager : Il gère les alertes en temps réel basées sur des déclencheurs.
Conçu pour être évolutif et flexible, Prometheus est capable de gérer des environnements de grande taille en agrégeant des données provenant de multiples sources. Sa flexibilité est renforcée par une communauté active qui contribue à une large gamme d’exporters et d’intégrations pour diverses applications et systèmes.
Opérateur Kubernetes pour Prometheus
Kubernetes offre de nombreux objets pour déployer vos applications : Pod, Deployment, Service, Ingress, etc. Ces ressources sont natives et, étant génériques, elles ne se comportent pas comme l’application finale. Kubernetes permet de créer des ressources personnalisées à l’aide des Custom Resource Definitions (CRD).
Les objets CRD implémentent le comportement de l’application finale. Cela permet une meilleure maintenabilité et réduit l’effort de déploiement. Lors de l’utilisation de l'opérateur Kubernetes Prometheus, chaque composant de l’architecture provient d’un CRD, ce qui rend la configuration de Prometheus plus simple que lors d’une installation classique.
Dans une installation classique de Prometheus, l’ajout de nouveaux points de métriques nécessite une mise à jour de la configuration du serveur pour enregistrer un nouveau point de terminaison comme cible de collecte des métriques. Le Prometheus Operator utilise des objets Monitor (PodMonitor, ServiceMonitor) pour découvrir dynamiquement les points de terminaison et collecter les métriques.
Déployer Prometheus avec Grafana
kube-prometheus-stack fournit une collection de plusieurs manifestes Kubernetes incluant des dashboards Grafana et des règles Prometheus. C'est un bon point de départ pour se familiariser avec l'observabilité et la stack Prometheus/Grafana. Cette installation fournit une solution de bout en bout pour surveiller un cluster Kubernetes en utilisant l'opérateur Prometheus.
Ajout du dépot Helm
Ajouter le dépôt Helm prometheus-community :
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
Mettez à jour vos dépots :
helm repo updateDéploiement du Helm chart
Déployer le Helm chart kube-stack-prometheus dans le namespace monitoring :
helm install --create-namespace --namespace monitoring kube-prometheus-stack prometheus-community/kube-prometheus-stack --set prometheus-node-exporter.hostRootFsMount.enabled=falsehostRootFsMount.enabled est configuré à false pour fonctionner avec Docker Desktop dans le cadre de ce tutorielLes Custom Resource Definitions sont maintenant installés dans le namespace monitoring. Vous pouvez voir les pods qui sont déployés dans le namespace :
kubectl get pods -n monitoringLe chart a installé les composants liés à Prometheus, l'opérateur Prometheus, Grafana et deux exporters :
- prometheus-node-exporter qui expose les métriques liés au hardware et à l'OS
- kube-state-metrics qui interroge l'API du serveur Kubernetes et qui va générer des métriques à propos des états des objets
Se connecter à l'interface de Prometheus
Les composants que nous avons déployé ne sont pas accessible publiquement. Il faut effectuer du port-forwarding avec cette commande pour accéder à l'interface web de Prometheus :
kubectl port-forward --namespace monitoring svc/kube-stack-prometheus-kube-prometheus 9090:9090L'interface de Prometheus est maintenant accessible sur http://localhost:9090. En naviguant dans le champ de requête, nous pouvons voir les différentes métriques disponibles :

En allant dans "Status > Targets", vous pouvez apercevoir tous les points d'accès des métriques découverts par le serveur Prometheus :


Se connecter à Grafana
La connexion à l’interface web de Grafana nécessite des identifiants qui sont stockés dans un Secret Kubernetes et encodés en base64.
Nous récupérons le nom d’utilisateur et le mot de passe avec ces deux commandes :
kubectl get secret --namespace monitoring kube-stack-prometheus-grafana -o jsonpath='{.data.admin-user}' | base64 -d
kubectl get secret --namespace monitoring kube-stack-prometheus-grafana -o jsonpath='{.data.admin-password}' | base64 -dPour accéder à l'interface de Grafana, c'est aussi un port-forward :
kubectl port-forward --namespace monitoring svc/kube-stack-prometheus-grafana 8080:80Ouvrez votre navigateur et allez sur http://localhost:8080, puis entrez les identifiants précédemment récupérés :

Le déploiement de kube-stack-prometheus a provisionné des tableaux de bord Grafana :
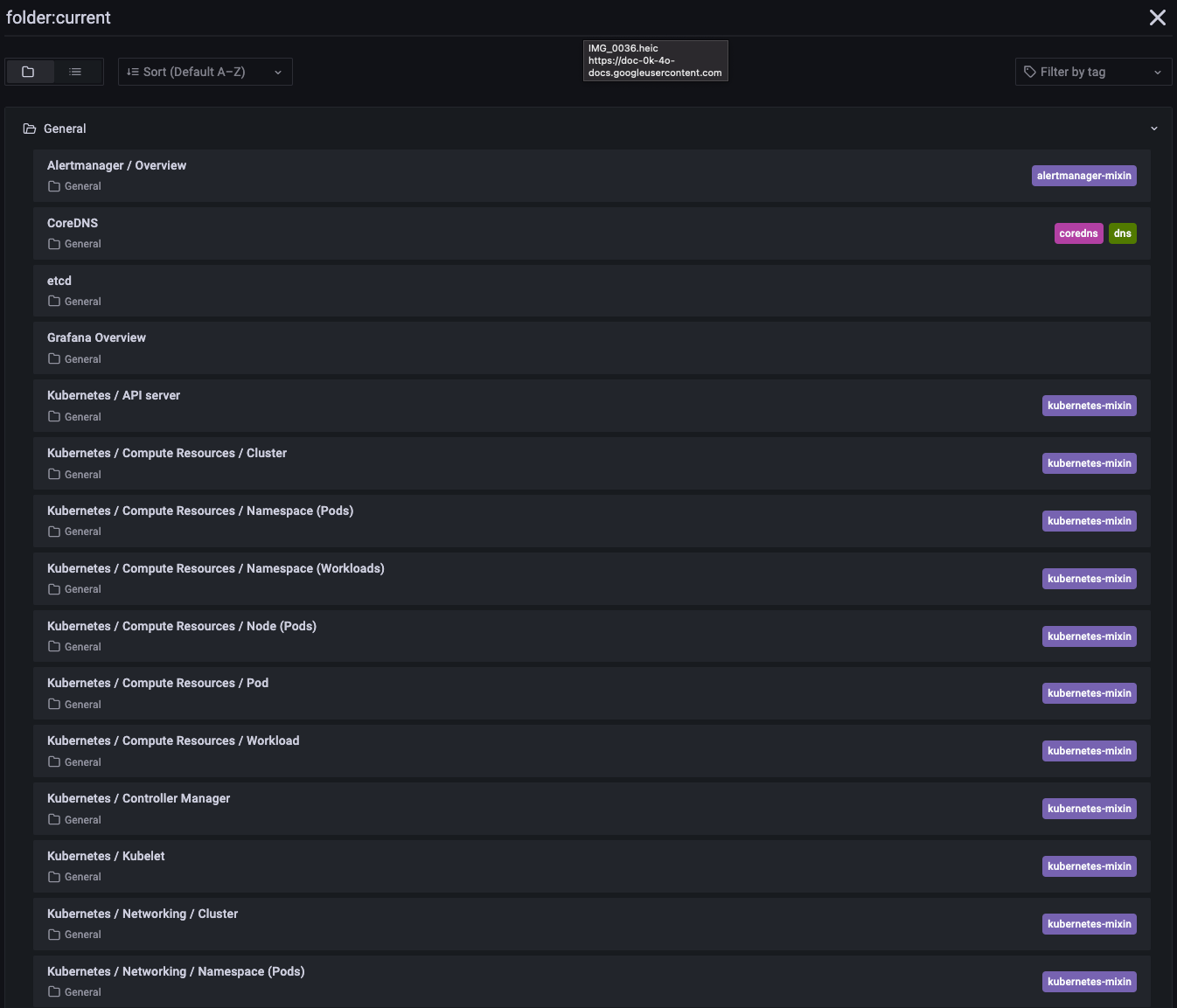
Ici, nous pouvons voir l’un d’entre eux affichant les ressources de calcul des pods Kubernetes :

Conclusion
En conclusion, la configuration de Prometheus et Grafana sur Kubernetes constitue une étape essentielle pour améliorer l’observabilité de vos systèmes. Grâce à Prometheus, vous pouvez collecter et analyser en profondeur les métriques de votre cluster, tandis que Grafana vous permet de visualiser ces données de manière claire et intuitive.
Ensemble, ces outils offrent une solution robuste pour surveiller la santé de vos applications et infrastructures, facilitant ainsi la détection des anomalies et l’optimisation continue de vos processus DevOps.
En suivant ce guide, vous avez mis en place une base solide pour garantir la stabilité et la performance de votre environnement Kubernetes.